Abstract
Preference-based Reinforcement Learning (PbRL) methods provide a solution to avoid reward engineering by learning reward models based on human preferences. However, poor feedback- and sample- efficiency still remain the problems that hinder the application of PbRL. In this paper, we present a novel efficient query selection and preference-guided exploration method, called SENIOR, which could select the meaningful and easy-to-comparison behavior segment pairs to improve human feedback-efficiency and accelerate policy learning with the designed preference-guided intrinsic rewards. Our key idea is twofold: (1) We designed a Motion-Distinction-based Selection scheme (MDS). It selects segment pairs with apparent motion and different directions through kernel density estimation of states, which is more task-related and easy for human preference labeling; (2) We proposed a novel preference-guided exploration method (PGE). It encourages the exploration towards the states with high preference and low visits and continuously guides the agent achieving the valuable samples. The synergy between the two mechanisms could significantly accelerate the progress of reward and policy learning. Our experiments show that SENIOR outperforms other five existing methods in both human feedback-efficiency and policy convergence speed on six complex robot manipulation tasks from simulation and four real-worlds.
Method
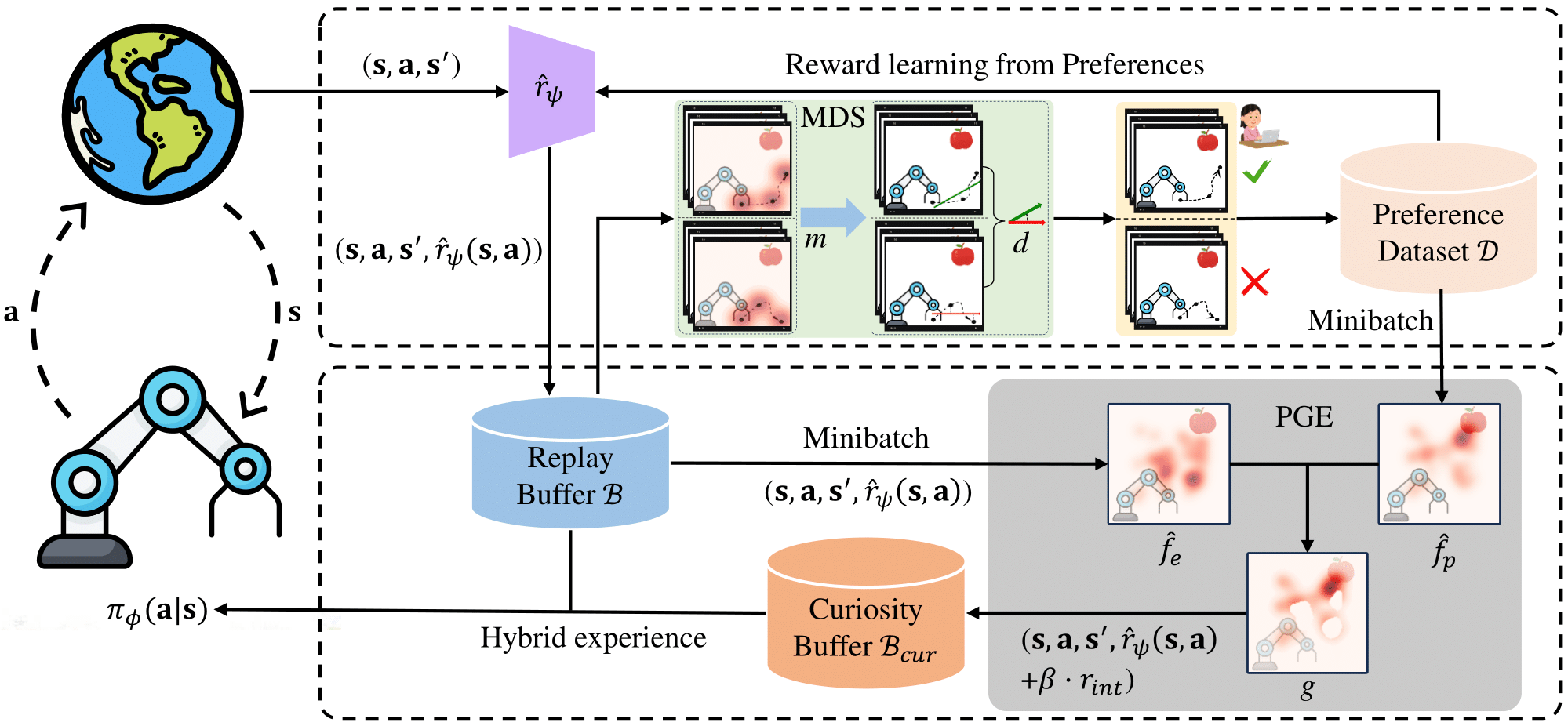
Figure 1: Illustration of SENIOR. PGE assigns high task rewards for fewer visits and human-preferred states to encourage efficient exploration through hybrid experience updating policy, which will provide query selection for more valuable task-relevant segments. MDS select easily comparable and meaningful segment pairs with apparent motion distinction for high-quality labels to facilitate reward learning, providing the agent with accurate rewards guidance for PGE exploration. During training, MDS and PGE interact and complement each other, improving both feedback- and exploration-efficiency of PbRL.